Object Storage와 연동
Object Storage와 Swift 연동
Hadoop Eco 서비스에서 Object Storage 데이터를 Swift와 연동하여 버킷에 접근할 수 있습니다.
Hadoop Eco 클러스터를 생성할 때 core-site.xml에 키를 설정해야 Object Storage의 데이터에 접근할 수 있습니다.
안내
Object Storage에 접근하기 위해서 액세스 키가 필요합니다. 카카오클라우드 콘솔 > 사용자 프로필 > 액세스 키에서 사용자의 자격 증명으로 액세스 키를 발급할 수 있습니다. 자세한 설명은 액세스 키 발급을 참고하시기 바랍니다.
클러스터 생성 시 추가(클러스터 상세 설정)
클러스터 생성 시 클러스터 상세 설정에 다음과 같이 작성합니다.
클러스터 상세 설정
{
"configurations": [
{
"classification": "core-site",
"properties": {
"fs.swifta.service.kc.credential.id": "credential_id",
"fs.swifta.service.kc.credential.secret": "credential_secret"
}
}
]
}
클러스터 생성 후 수정(core-site.xml 수정)
클러스터 생성 후 수정할 경우, /etc/hadoop/conf/core-site.xml 파일에 다음과 같이 액세스 키 정보를 입력합니다.
core-site.xml 수정
<configuration>
<property>
<name>fs.swifta.service.kc.credential.id</name>
<value>credential_id</value>
</property>
<property>
<name>fs.swifta.service.kc.credential.secret</name>
<value>credential_secret</value>
</property>
</configuration>
사용 예제
Object Storage의 스키마는 다음과 같습니다.
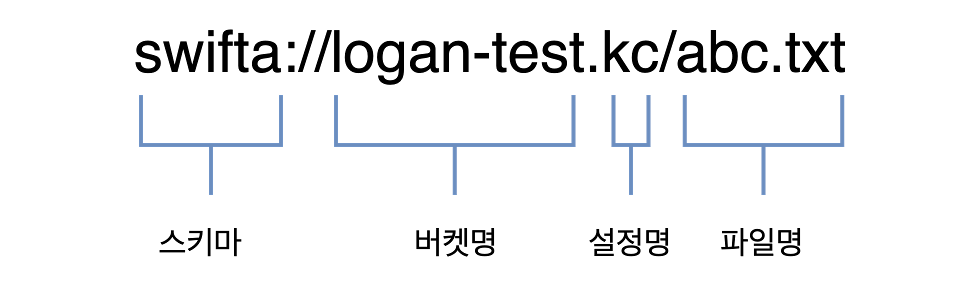 Object Storage의 스키마
Object Storage의 스키마
Hadoop
Hadoop의 ls, mkdir, put, get 등 fs 명령을 이용해서 Object Storage의 데이터를 확인할 수 있습니다.
Hadoop - object Storage
$ hadoop fs -ls swifta://logan-test.kc/
Found 2 items
-rw-rw-rw- 1 ubuntu ubuntu 6 2021-07-14 02:30 swifta://logan-test.kc/abc.txt
drwxrwxrwx - ubuntu ubuntu 0 2021-07-14 04:12 swifta://logan-test.kc/user
Hive
테이블을 생성할 때 LOCATION을 Object Storage로 지정해서 데이터를 확인할 수 있습니다.
Hive - Object Storage
-- 테이블 생성 시 LOCATION을 Object Storage로 지정
CREATE EXTERNAL TABLE tb_objectstorage (
col1 STRING
)
LOCATION 'swifta://logan-test.kc/tb_objectstorage'
;
-- 데이터 입력
insert into table tb_objectstorage values ('a'), ('b'), ('c');
-- 조회
select col1, count(*) from tb_objectstorage group by col1;
# Hadoop 명령으로 확인
$ hadoop fs -ls swifta://logan-test.kc/tb_objectstorage
Found 1 items
-rw-rw-rw- 1 ubuntu ubuntu 16 2022-03-31 06:16 swifta://logan-test.kc/tb_objectstorage/000000_0.snappy
Spark
Spark에서 데이터를 읽을 위치를 Object Storage로 지정해서 활용할 수 있습니다.
Spark - Object Storage
$ ./bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/04/01 05:54:58 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://hadoopmst-hadoop-single-1:4040
Spark context available as 'sc' (master = yarn, app id = application_1648703257814_0004).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> val peopleDF = spark.read.format("json").load("swifta://logan-test.kc/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [name: string]
scala> peopleDF.show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
Trino
Trino에서 생성한 Object Storage 연동 테이블을 확인할 수 있습니다.
Trino - Object Storage
# hive 테이블 확인
hive (default)> desc formatted t2;
OK
col_name data_type comment
# col_name data_type comment
col1 string
# Detailed Table Information
Database: default
Owner: ubuntu
CreateTime: Thu Jul 14 00:14:27 UTC 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: swifta://logan-test.kc/t2
Table Type: MANAGED_TABLE
Table Parameters:
STATS_GENERATED_VIA_STATS_TASK workaround for potential lack of HIVE-12730
numFiles 9
totalSize 165
transient_lastDdlTime 1657757711
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 8.039 seconds, Fetched: 28 row(s)
# trino 데이터 조회, 입력
$ trino --server http://hadoopmst-trino-ha-3:8780 --catalog hive
trino> select col1, count(*) from default.t2 group by col1;
col1 | _col1
------+-------
b | 6
dd | 1
aa | 1
c | 6
a | 6
(5 rows)
Query 20220714_001621_00000_3xb9i, FINISHED, 3 nodes
Splits: 64 total, 64 done (100.00%)
6.18 [20 rows, 142B] [3 rows/s, 23B/s]
trino>
trino> insert into default.t2 values ('kk');
INSERT: 1 row
Query 20220714_001659_00001_3xb9i, FINISHED, 4 nodes
Splits: 37 total, 37 done (100.00%)
7.47 [0 rows, 0B] [0 rows/s, 0B/s]